


I’ve been experimenting and using the citiation mapping fuction in VOSViewer for a few weeks now and I’ve started working with the plain text mapping function. VOSViewer supports what it calls a ‘corpus’ file, which is a plain text files with each of your individual documents held in a single line, with a carriage return at the end.
The installed version of VOSViewer has an example corpus file that you can work on.
http://www.vosviewer.com/download
I wanted to throw something a little more challenging at VOSViewer to check out how well it handled a larger text file.
I created a corpus using all of Jane Austen’s novels available on the Project Gutenberg site.
Sense and Sensibility (1811)
Pride and Prejudice (1813)
Mansfield Park (1814)
Emma (1815)
Northanger Abbey (1818)
Persuasion (1818)
Lady Susan (1871)
The leading and trailing Project Gutenberg information was removed, as well as all of the extra line breaks and carriage returns.
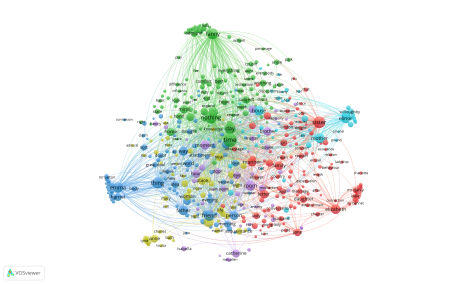
This was then loaded into VOSViewer, where we used the ‘Full Counting’ method. The minimum number of occurrences of a term was set at 50. This leaves 472 of 23000+ terms, and I decided to map all of the terms.
You can go through and remove unwanted terms, and I’ll show an example of that slightly later.

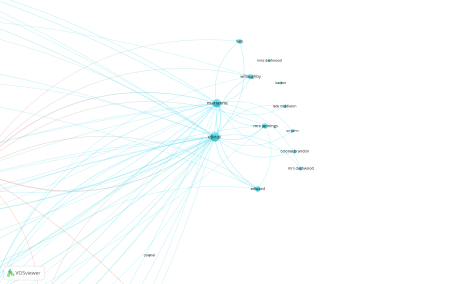
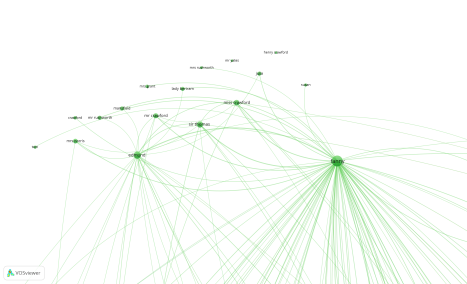
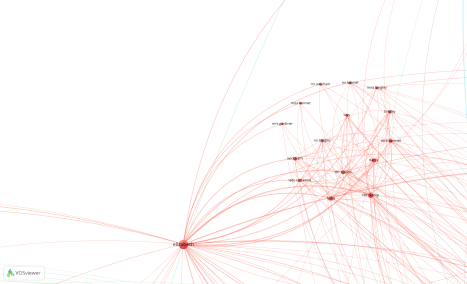
As an example of limited terms, I ran through the import process using the same settings and only kept references to people (father, sister, cousin etc and specific names)



VOSViewer is a really remarkable tool, adding abilities to analyze the relatedness of a very large text corpus in ways that would be very difficult only a few months ago. I anticipate that this particular example will be of particular interest to fans of Jane Austen.
This is just a very rough run through, without any attempt to create a master file of names or make any conclusions. But the power of VOSViewer for text analysis is really obvious in these maps.
Filed under: Apps, Uncategorized | Tagged: Digital Humanities, Digital Libraries, History, Jane Austen, Text Mining | Leave a comment »

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}